Ранее мы отметили, что библиотека pandas прекрасно справляется с работой с датами. Однако она столь же эффективна в операциях с текстовыми данными. Давайте вернемся к исходным данным из предыдущей части.
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
pd.options.display.max_rows = 7
plt.style.use('ggplot')
plt.rcParams['figure.figsize'] = (15, 3)
plt.rcParams['font.family'] = 'sans-serif'
weather_2012 = pd.read_csv('data/weather_2012.csv', parse_dates=True, index_col='Date/Time')
weather_2012[:5]
Работа с текстовыми данными в pandas
Погоду за каждый час описывает столбец 'Weather'. Допустим, что запись о снежной погоде включает слово "Snow".
С помощью pandas можно эффективно выполнять векторизированные операции над строками в столбцах. В документации вы найдете множество полезных примеров.
weather_description = weather_2012['Weather']
is_snowing = weather_description.str.contains('Snow')
Данный код создает двоичный вектор, который не очень нагляден, поэтому давайте построим график.
is_snowing[:5]
is_snowing.plot()
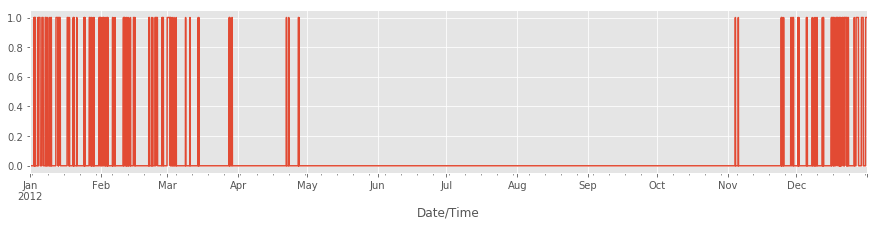
Находим месяцы с максимальным количеством выпавшего снега
Чтобы вычислить медианную температуру за каждое месяц, необходимо применить метод resample(), как в приведенном далее примере:
weather_2012['Temp (C)'].resample('M').median().plot(kind='bar')
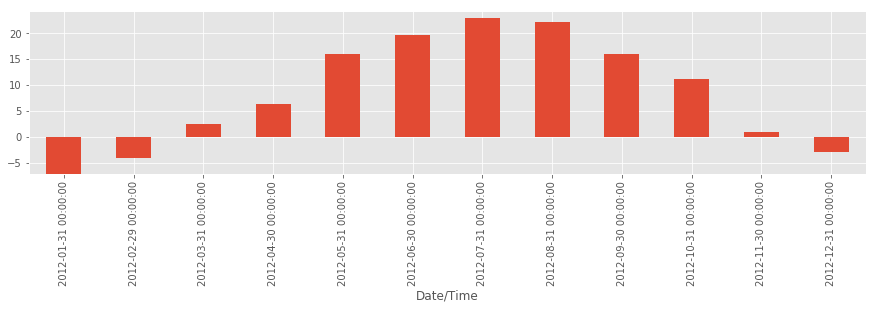
Неожиданно, самыми жаркими оказались июль и август.
Что касается снега, вместо значений True или False мы можем рассматривать наш вектор как состоящий из нулей и единиц:
is_snowing.astype(int)[:10]
а затем применить метод resample, чтобы определить процент времени, когда снег действительно выпадал.
is_snowing.astype(int).resample('M').mean()
Date/Time
2012-01-31 0.240591
2012-02-29 0.162356
2012-03-31 0.087366
...
2012-10-31 0.000000
2012-11-30 0.038889
2012-12-31 0.251344
Freq: M, Name: Weather, dtype: float64
is_snowing.astype(int).resample('M').mean().plot(kind='bar')
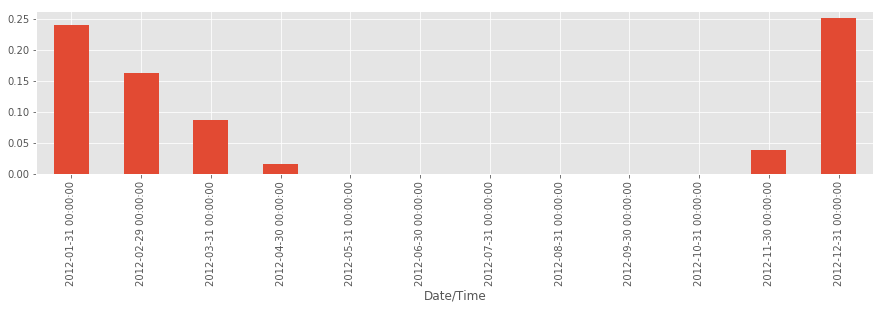
Теперь мы убедились! В 2012 году самым снежным оказался декабрь.
Объединяем графики температур и снежных условий
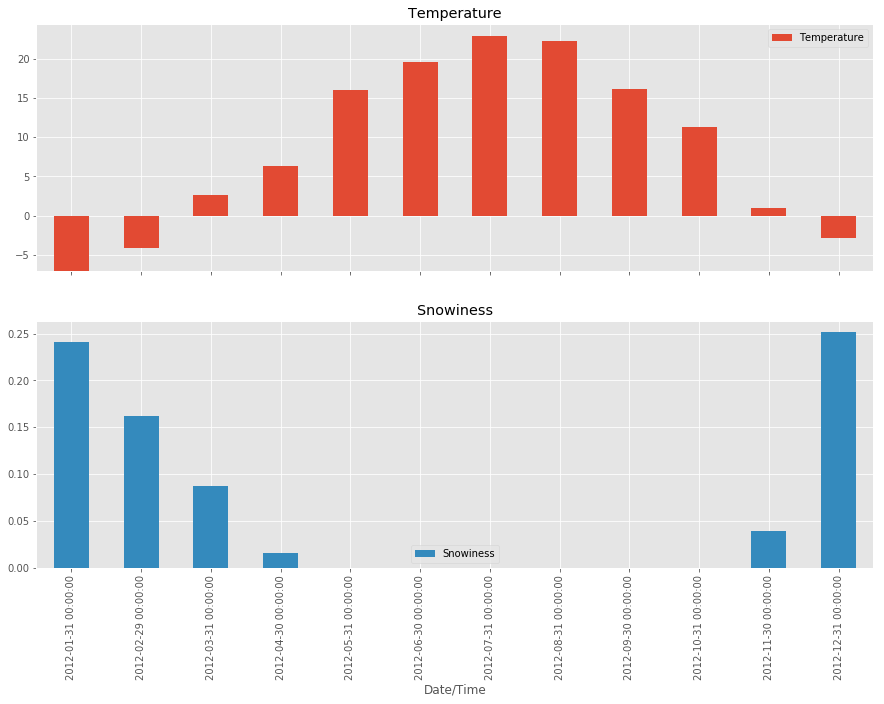
Для большей наглядности объединим эти две статистики в один DataFrame, затем изобразим их вместе:
temperature = weather_2012['Temp (C)'].resample('M').median()
is_snowing = weather_2012['Weather'].str.contains('Snow')
snowiness = is_snowing.astype(int).resample('M').mean()
# Name the columns
temperature.name = "Temperature"
snowiness.name = "Snowiness"
Используйте concat для объединения этих колонок в единый DataFrame.
stats = pd.concat([temperature, snowiness], axis=1)
stats
stats.plot(kind='bar')
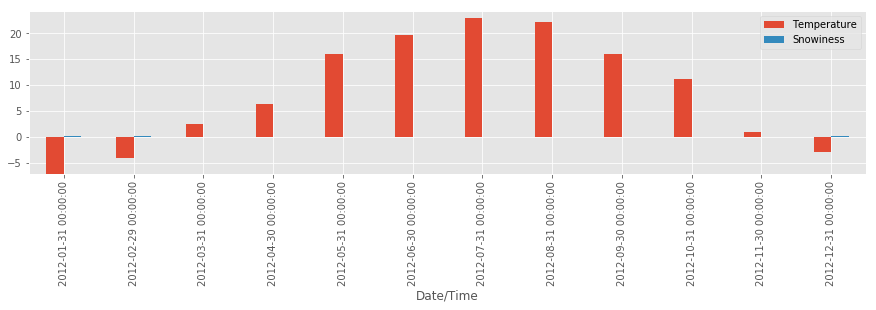
Увы, это не сработает, потому что шкалы выбраны неверно. Построим графики раздельно на двух разных осях:
stats.plot(kind='bar', subplots=True, figsize=(15, 10))