Создание HTML — это увлекательный процесс, но что делать, если что-то вдруг не работает? В этой статье представлены несколько инструментов для поиска и устранения ошибок в HTML.
| Требуемые знания: | Основы HTML, которые изложены в Основы HTML - элементы, атрибуты и теги. Форматирование текста через HTML описано в материале Основы редактирования текста в HTML. Работа с гиперссылками раскрыта в разделе Создание и настройка гиперссылок в HTML. |
|---|---|
| Задача: | Научиться находить ошибки в HTML с помощью инструментов отладки. |
Отладка — это не так страшно
Обычно при написании какого-либо кода все идет по плану, до тех пор, пока не возникает ошибка. Ваш код может перестать функционировать или работать не так, как хотелось бы. Например, если вы пытаетесь скомпилировать некорректную программу на языке Rust, компилятор укажет вам на ошибку:
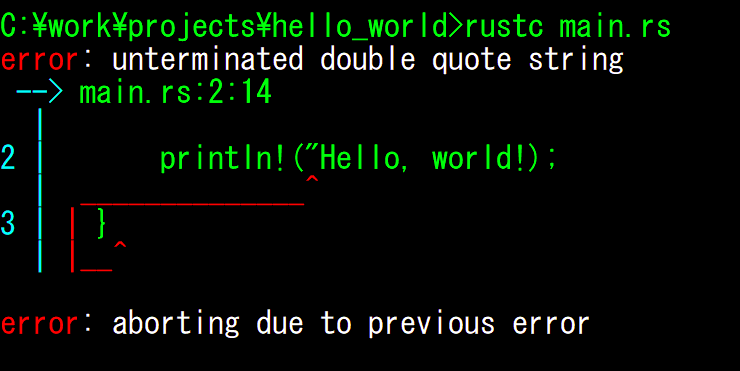
Это сообщение об ошибке довольно простое для понимания — "unterminated double quote string". Если внимательно проанализировать
строку println!("Hello, world!);, становится ясно, что недостает двойной кавычки. Конечно,
сообщения об ошибках могут стать значительно сложнее по мере усложнения кода, и даже простые ситуации могут показаться
запутанными для тех, кто еще не знаком с Rust.
Не пугайтесь отладочных задач! Чтобы эффективно писать и отлаживать код, необходимо понимать язык программирования и пользоваться его инструментами.
HTML и отладка
HTML проще для понимания, чем Rust. Он не компилируется в другие формы перед отображением в браузере (является интерпретируемым, а не компилируемым). Синтаксис элементов HTML гораздо читабельнее, чем у программных языков вроде Rust, JavaScript или Python. Браузеры интерпретируют HTML более толерантно, чем языки программирования, которые строго проверяют код. Это как достоинство, так и недостаток.
Толерантность к ошибкам
Что подразумевается под словом "толерантность"? В основном, это означает, что при наличии ошибок в коде существуют два их типа:
- Синтаксические ошибки (Syntax errors): Это ошибки в форме записи, как в предыдущем примере с Rust. Они обычно легко исправляются, если вы знакомы с синтаксисом и ошибками, о которых идет речь.
- Логические ошибки (Logic errors): Эти ошибки возникают, когда синтаксис корректен, но код не решает поставленную задачу, то есть программа работает неправильно. Их сложнее выявить, так как сообщения об ошибках отсутствуют.
HTML не так строго относится к синтаксическим ошибкам, так как браузер читает код толерантно — страницы могут отображаться даже при наличии синтаксических ошибок. Браузеры имеют встроенные механизмы для интерпретации некорректной разметки, и результат может быть исполнен, даже если он окажется другим, чем вы планировали. Это может вызвать серьезные сложности!
Толерантное отношение к HTML обосновано тем, что в начале развития веба было решено позволять публиковать контент даже с ошибками, чтобы гарантировать доступность информации. Быстрая адаптация новичков важнее строгой корректности.
Практика: Изучение толерантности к ошибкам
Пришло время ознакомиться с толерантным кодом в HTML.
-
Во-первых, ознакомьтесь с примером ниже (приведено только тело). В этом примере
специально допущены ошибки, которые предстоит обнаружить.
<h1>HTML debugging examples</h1> <p>What causes errors in HTML? <ul> <li>Unclosed elements: If an element is <strong>not closed properly, then its effect can spread to areas you didn't intend <li>Badly nested elements: Nesting elements properly is also very important for code behaving correctly. <strong>strong <em>strong emphasised?</strong> what is this?</em> <li>Unclosed attributes: Another common source of HTML problems. Let's look at an example: <a href="https://ask42.us/course/html-introduction/chapter/debug/>link to current page</a> </ul>
- Поместите представленный HTML-фрагмент в body тэг валидного HTML-документа и ознакомьтесь с его отображением в браузере.
-
Обратите внимание на проблемы:
- В параграфе и элементе списка пропущены закрывающие теги. Разметке это не сильно навредило, так как браузер успешно определяет, где заканчивается один элемент и начинается другой.
- Первый <strong> элемент не закрыт. Это создает более значительные проблемы, так как трудно определить место завершения элемента. По факту, весь последующий текст стал выделенным жирным.
-
Следующая часть нарушает правила вложенности:
<strong>strong <em>strong emphasised?</strong> what is this?</em>. Это вызывает затруднения с интерпретацией, как уже было упомянуто ранее. - В атрибуте href отсутствует закрывающая двойная кавычка, из-за чего ссылка не воспроизводится.
- Давайте посмотрим, как браузер восстановил разметку, в отличие от исходного кода документа. Чтобы просмотреть это, используем инструменты разработчика.
-
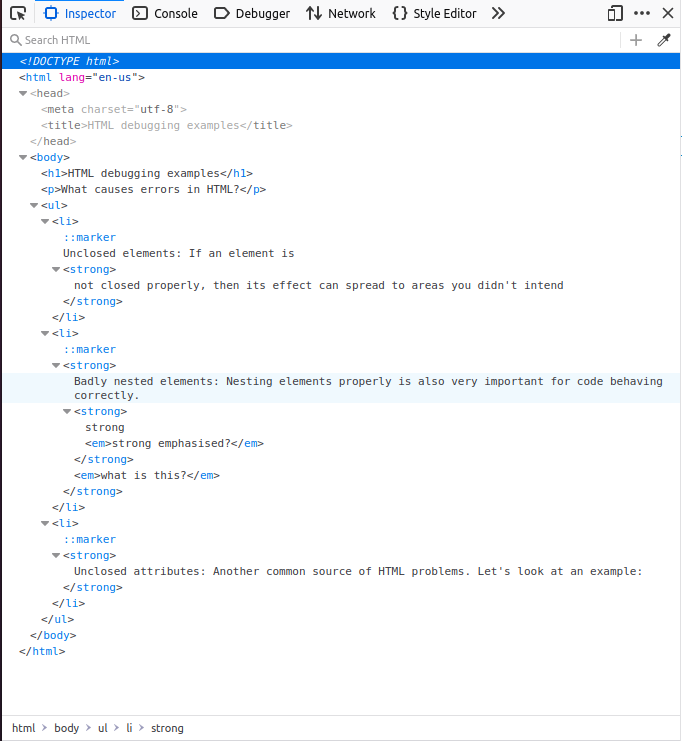
В DOM инспекторе можно увидеть, чем браузер заменил изначальную разметку:
-
Используя DOM инспектор, давайте исследуем детали, чтобы увидеть, как браузер корректирует ошибки в HTML. Мы будем рассматривать
пример в Firefox; так же должно быть и в других современных браузерах:
- Параграфы и элементы списка получили закрывающие теги.
- Поскольку закрывающий тег для <strong> трудно определить, браузер добавил теги strong к каждому блоку текста самостоятельно, причем до конца документа!
-
Некорректная вложенность была исправлена браузером следующим образом:
<strong>strong <em>strong emphasised?</em> </strong> <em> what is this?</em>
-
Ссылка с отсутствующими кавычками была полностью удалена. Элемент списка выглядит так:
<li> <strong>Unclosed attributes: Another common source of HTML problems. Let's look at an example: </strong> </li>
Проверка валидности HTML
Приведенный пример демонстрирует важность проверки валидности HTML. В небольшой демонстрации ошибки можно выявить, просмотрев код, но что делать с более сложными страницами?
Лучший способ — использовать HTML-валидатор. Этот сервис разработан и поддерживается W3C — организацией, устанавливающей стандарты для HTML, CSS и прочих веб-технологий. В результате проверки будет составлен отчет об ошибках в вашем HTML.
Проверка HTML возможна через URL, загрузку файла или копирование содержимого страницы.
Анализ сообщений об ошибках
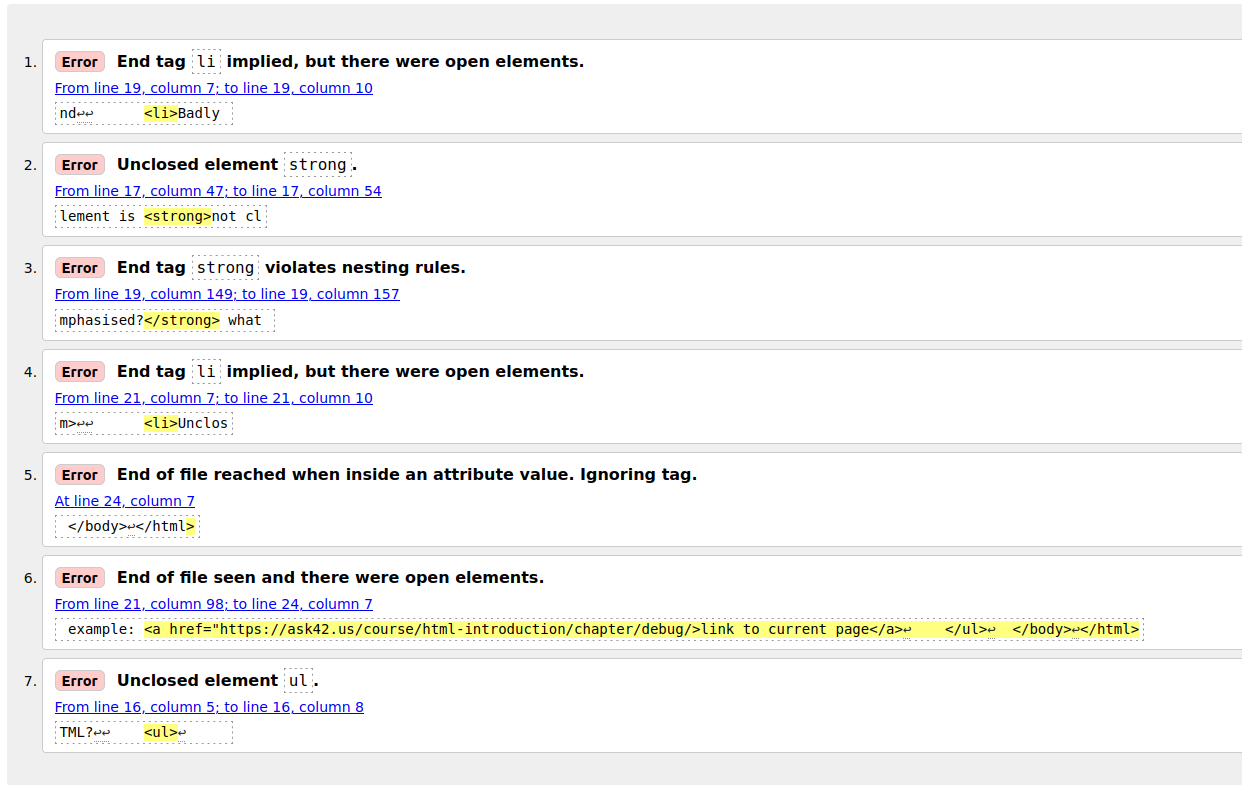
В большинстве случаев смысл сообщений об ошибках ясен, однако иногда требуется дополнительный анализ для выявления проблемы. Давайте разберем каждую ошибку из списка и обсудим их значения. Обратите внимание, что сообщения содержат указания на номер строки и столбца, что облегчает поиск ошибок в коде.
- "End tag li implied, but there were open elements" (2 instances): Отсутствует явный закрывающий тег, но браузер приблизительно предполагает его местоположение. Сообщение указывает на строку, следом за которой предполагался закрывающий тег, но нужное место можно легко обнаружить.
- "Unclosed element strong": Это простая ошибка — отсутствует закрывающий тег элемента <strong>, и сообщение напрямую указывает на это.
- "End tag strong violates nesting rules": Элемент неправильно вложен, так как на этом уровне нет соответствующего открывающего тега.
- "End of file reached when inside an attribute value. Ignoring tag": Непонятное сообщение, но связано оно с тем, что где-то, вероятно, в конце документа неверно установлено свойство элемента — конец файла оказался внутри этого свойства. В браузере ссылка не отображается, вероятно, проблемы именно здесь.
-
"End of file seen and there were open elements": Файл завершился, но не все элементы закрыты. Сообщение указывает на конец
файла, где в данном случае не закрыт элемент
example: <a href="https://ask42.us/course/html-introduction/chapter/debug/>link to current page</a> ↩ </ul>↩ </body>↩</html>
ПримечаниеНезакрытый атрибут может поглотить закрывающий тег — браузер расценит его как часть значения атрибута.
- "Unclosed element ul": Это странно, так как элемент <ul> все-таки закрыт. Проблема все та же — не закрыт элемент <a> из-за пропущенной закрывающей кавычки в атрибуте.
Если некоторые ошибки кажутся непонятными, начните с исправления более очевидных, после чего проверьте документ повторно. Иногда одна ошибка способна нарушить форматирование большинства документа.
Если вы увидели подобное сообщение, значит, ваш документ более не содержит ошибок:

Заключение
Теперь вы знаете, как отлаживать HTML. Этот опыт поможет вам также при работе с более сложными языками, такими как CSS и JavaScript. Завершив вводный курс по HTML, попробуйте себя в выполнении упражнений.